Machine Learning Explained
Faculty Mentor:
Dr.Deepti Sharma
Student Name:
Kapil Goel (MCA – I)
1.INTRODUCTION
Machine learning is about extracting knowledge from data. It is a research field at the intersection of computer science, statistics and artificial intelligence. Machine learning is enabling computers to tackle tasks that have, until now, only been carried out by people. It uses the data to detect patterns in a dataset and adjust program actions accordingly and focuses on the development of computer programs that can teach themselves to grow and change when exposed to new data. It enables computers to find hidden insights using iterative algorithms without being explicitly programmed.
2.DIFFERENCE IN MACHINE LEARNING AND TRADITIONAL PROGRAMMING
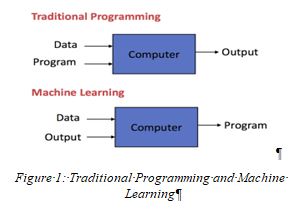
- Traditional Programming: In Traditional programming, we have to code step by step instructions to perform a task.
- Machine Learning: In a machine learning system, the system learns from the data itself. This technique is more appropriate if the rules necessary to solve the problem at hand are too many and too complex to code using traditional approaches.
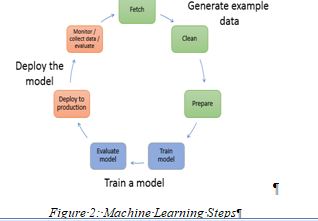
3.MACHINE LEARNING STEPS
Step 1: Collecting Data: The first step is data collection and this stage involves the collection of all relevant data from various sources.
Step 2: Data Wrangling: Now the Second step after collecting all the data is data wrangling which is the process of cleaning and converting the raw data into a format that allows convenient consumption.
Step 3: Analyze Data: Now after the data have been cleaned and converted into a particular format, the data is analyzed to select and filter the data required to prepare the model because not all the data is required for a particular model. We have to select certain features.
Step 4: Train Algorithm: Now after selecting the features, the algorithm is trained on the training data set through which the algorithm understands the pattern and the rules which govern the data.
Step 5: Test Algorithm: After this, the testing dataset determines the accuracy of the model. If the speed and the accuracy of the model is acceptable, then that model should be deployed in the real system.
Step 6: Deployment: The model is deployed based upon its performance. The model is updated and improved and if there’s a dip in the performance, the model is retrained.
4.TYPES OF MACHINE LEARNING
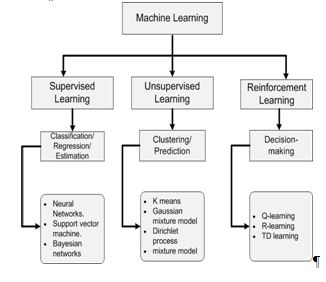
- SUPERVISED LEARNING
Supervised Learning is a form of machine learning where the machine is taught using labelled data. Supervise means directing for an activity to do. The machine learns itself under guidance in this type of learning. It is done by explicitly guiding the machine that how the input should be taken and thus how the output will come.
- TYPES OF PROBLEMS THAT ARE SOLVED USING SUPERVISED LEARNING
Supervised learning is divided into two main categories of problems. One is regression and other is classification problems.
- Classification: Classification deals with a label, class or any discrete values whereas regression deals with a continuous quantity. Suppose we can classify emails into spam or non-spam emails. In this type of problem, we can use classification.
- Regression: Regression is used to predict a continuous quantity. Now a continuous variable is a variable that has an infinite number of possibilities. For example, a person’s weight. So, someone could be 180 pounds or they could be 180.10 pounds or 180.110 pounds.
- TYPES OF DATA
In supervised learning, the data with input and output will be provided to machines at the time to training. The output of the algorithm is feeded into the system. In supervised learning, the output of the algorithm is already known by the machine before it starts working on it. An example of supervised learning is classifying a data set into either boy or girl. If the algorithm is provided an image of a boy the image is labelled as a boy. This is how the model works. By labelling it, machine is taught that this is a boy. After the algorithm has learned, it is then tested using a new data.
- TRAINING
In supervised learning, the training phase is well defined and very explicit. Training data is fed into the machine. And both the input and output are labelled. The training data acts like a teacher or a guide. Algorithm maps the input to the output. After the algorithm has been trained, it is tested using the new data.
- AIM
The main aim of a supervised learning algorithm is to forecast an outcome. Forecasting an outcome is the basic aim of all types of machine learning algorithms. But the whole process of supervised learning is such that it can directly give you a forecast because supervised learning algorithms have a very well-defined and explicit training phase.
- APPROACH FOLLOWED
In supervised learning machine algorithms, known input is mapped to the known output.
- FEEDBACK
In supervised learning machine algorithms, since the machine is trained with both output and input, there is a direct feedback mechanism.
- ALGORITHMS
Some of the algorithms in supervised learning are linear regression, support vector machines, decision trees. These can be used for both classification and regression problems. Linear regression is mainly used for regression problems.
- APPLICATIONS
Supervised learning is widely used in the business sector. Applications of supervised learning are predicting sales profit, risk analysis, forecasting risks, and so on.
- UNSUPERVISED LEARNING
In unsupervised learning, the unlabeled data is fed to the machine. and the machine has to learn without any supervision. And that’s why it should detect hidden trends and patterns in the data. Unsupervised means to act without anybody’s direction or supervision. An example of unsupervised learning is an adult who don’t need a guide to help him with his daily chores. Without any supervision, he can figure things on his own.
- TYPES OF PROBLEMS THAT ARE SOLVED USING UNSUPERVISED LEARNING
With this type of learning we can solve clustering problems and association problems.
- Association Problems: Association problems involves finding co-occurrences and discovering patterns in data, and so on. Association problems mainly involve discovering associations between items that co-occur frequently.
- Clustering Problems: Clustering is widely used in cases wherein we are provided a list of customers and some information about them and we are required to cluster these customers based on their similarity. Clustering is very useful for targeted marketing.
- TYPES OF DATA
In unsupervised learning, we give the machine only the input data. Here the system is not told where to go. The system has to understand itself using the input data that we feed to it. It does this by discovering patterns in the data. So, if we try to classify images into boys and girls, the machine will be provided images of boys and girls and at the end, two groups will be formed. One group will contain boys and the other will contain girls. Now the important point here is that labels won’t be added to the output. The machine will just understand how boys look and will cluster them into one group and similarly for girls.
- TRAINING
In unsupervised learning, since the machine is only provided the input, it has to figure out the output on its own. So, the training phase is very big here. There's no supervisor in this type of learning.
- AIM
The main goal of unsupervised learning is finding patterns in the data and extracting useful insights. Since only input is fed to the algorithm, the machine has to find a way to get to the output. This is done by discovering associations and trends in the data.
- APPROACH FOLLOWED
In unsupervised learning, all the trends and patterns in data are discovered by the algorithm. Until the algorithm reaches the output, it keeps exploring the data.
- FEEDBACK
In Unsupervised learning, since the machine does not know the output during the training phase, there is no feedback mechanism.
- ALGORITHMS
Some of the algorithms in unsupervised learning are k-Means for clustering analysis, Apriori and Association rule mining for solving Association problems.
- APPLICATIONS
When we buy an item on Flipkart or on any other online shopping portal, we get a list of recommendations. These recommendations that we see are all done by unsupervised learning. Anomaly Detection and Credit card fraud detection are some of the other applications of unsupervised Learning.
- REINFORCEMENT LEARNING
Reinforcement means establishing or encouraging a pattern of behavior. In reinforcement learning, there is an agent which is put in an unknown environment. To explore the unknown environment, the agent transitions from one state to the other and takes actions so that he can get maximum rewards.
- TYPES OF PROBLEMS THAT ARE SOLVED USING REINFORCEMENT LEARNING
In reinforcement learning, the actions we take is dependent on the input. For example, in robotics, the robot might start in a scenario where it has no knowledge about the surrounding it is in. It finds out more about the surrounding world by performing certain actions. The world it sees depends on whether it chooses to move left, right, forward or backward. In this situation, the agent is the robot and the environment are its surrounding. The robot takes actions such that it receives minimum punishments or maximum rewards.
- TYPES OF DATA
For reinforcement learning, data is not predefined. The actions taken by the agent decides the input. These actions are then recorded in the form of matrices which later acts as a memory for the agent. The agent will collect data as it explores the environment. This data is then used to get the output. So, in reinforcement learning, the dataset fed to the machine is not predefined. All the work has to be performed from scratch by the agent.
- TRAINING
The whole reinforcement learning process itself is a training and testing phase since there is no predefined data given to the machine. It has to learn everything on its own.
- AIM
In reinforcement learning, the agent is a very similar to a human baby. Initially the agent also has no idea about its environment just like how a baby is clueless about the world he is in. The agent starts learning as it starts exploring its environment. Mistakes made by agent help it learn.
- APPROACH FOLLOWED
The approach followed by reinforcement learning is a trial and error method, the trial and error method best explain reinforcement learning because the agent has to try out all the possible actions to learn about its environment and to get maximum rewards.
- FEEDBACK
In reinforcement learning, the feedback is in the form of rewards or punishments from the environment so when an agent takes a suitable action it will get a corresponding reward for that action but if the action is wrong then it gets a punishment.
- ALGORITHMS
Reinforcement learning is just being explored recently. A few algorithms include Q learning andState–action–reward–state–action (SARSA) algorithm.
- APPLICATIONS
Reinforcement learning is used in self-driving cars, in building games and all of that one famous example is the AlphaGo game.
5.COMMON MACHINE LEARNING ALGORITHMS
- LINEAR REGRESSION: Linear Regression is a machine learning algorithm which is based on supervised learning. It performs a regression task. Linear regression attempts to model the relationship between two variables by setting a linear equation to the observed data. One variable is considered to be an independent variable while the other is considered to be a dependent variable.
- LOGISTIC REGRESSION: Logistic regression predictions are discrete values (i.e., whether a student failed/passed) after applying a transformation function whereas linear regression predictions are continuous values (i.e., height in cm).
Logistic regression is suitable for binary classification. It is used in predicting whether an event will occur or not, in cases where there are only two possibilities: that it occurs (denoted as 1) or that it does not (0). So, if we were predicting whether a student has passed, we would label passed students using the value of 1 in our data set.
- NAÏVE BAYES: We use Bayes’s Theorem to calculate the probability that an event will occur, given that another event has already occurred. We use Bayes’s Theorem as follows:
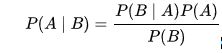
where A and B are events and P(B) ≠ 0
Some of real-world examples are:
- Marking an email as spam or not spam
- Classifying a news article about sports, technology or politics
- K-MEANS: K-means clustering is a very popular and simple unsupervised machine learning algorithm. K-means Clustering is used for relationship discovery and understanding the underlying structure of data. It is useful for unlabeled data as a first round of analysis. It makes no assumptions on data. It is manually given a target number of clusters. It utilizes a distance metric and clustering algorithm.
- DECISION TREE:A decision tree takes as input an object/situation described by a set of properties and outputs a no/yes "decision". We first describe the representation—the hypothesis space— and then show how to learn a good hypothesis. It is a tree structured classifier, which is tree structured and it has two types of nodes, decision nodes, and leaf nodes. In decision nodes, they specify a choice or a test based on which you can decide which direction you can go. And then, there are leaf nodes. Leaf nodes give the value to be returned if that leaf is reached. Decision trees are mostly used for classification, though it can also be used for regression.
- KNN: K Nearest Neighbor (KNN) is a simple algorithm that stores all the available cases and classifies the new data or case based on a similarity measure.
- Uses the intuition to classify a new point x
- find the most similar training example x'
- predict its class y'
- Voronoi tessellation
- partitions space into regions
- boundary: points at the same distance from two different training examples
- classification boundary
- non-linear, reflects classes well
- SUPPORT VECTOR MACHINE (SVM): SVM or support vector machine is a supervised learning algorithm that is mainly used to classifydata into different classes. Unlike most algorithms SVM makes use of a hyperplane which acts as a decision boundary between the various classes. SVM can be used to generate multiple separating hyperplanes so that the data is divided into segments and each of these segments will contain only one kind of data. It is mainly used for classification purposes wherein you want to classify data into two different segments depending on the features of the data.
- NEURAL NETWORK: A neural network is a network of neurons, or an artificial neural network, composed of artificial neurons for solving artificial intelligence (AI) problems. The connections of the biological neuron are modelled as weights. An excitatory connection is reflected by a positive weight, while inhibitory connections are reflected by negative values. All inputs are modified by a weight and summed. This activity is known as linear combination. Lastly, an activation function controls the amplitude of the output. These artificial networks are used for adaptive control, predictive modelling, and applications where they can be trained via a dataset.
- RANDOM FORESTS: Random Forest or Random Decision Forest is a method that operates by constructing multiple Decision trees during the training phase. The decision of the majority of the trees is chosen by the random forest as the final decision.
Advantages of Random Forests are:
- Training time is less.
- Runs efficiently on a large database.
- For large data, it produces highly accurate predictions.
- Random Forest can maintain accuracy when a large proportion of data is missing.
- APRIORI ALGORITHM: Apriori is an algorithm for association rule learning and frequent itemset mining over transactional databases. It works by identifying the frequent individual items in the database and extending them to larger and larger item sets until those item sets appear sufficiently often in the database. The frequent itemset determined by Apriori can be used to determine association rules which highlight general trends in the database. This algorithm has applications in domains such as market basket analysis.
6.REFERENCES
[1]https://www.profolus.com/topics/benefits-limitations-of-machine-learning/
[2]https://www.getfilecloud.com/blog/2018/06/top-5-limitations-of-machine-learning-in-an-enterprise-setting/
[3]https://www.edureka.co/blog/what-is-machine-learning
[4]https://en.wikipedia.org/wiki/Machine_learning
[5]https://www.geeksforgeeks.org/machine-learning/